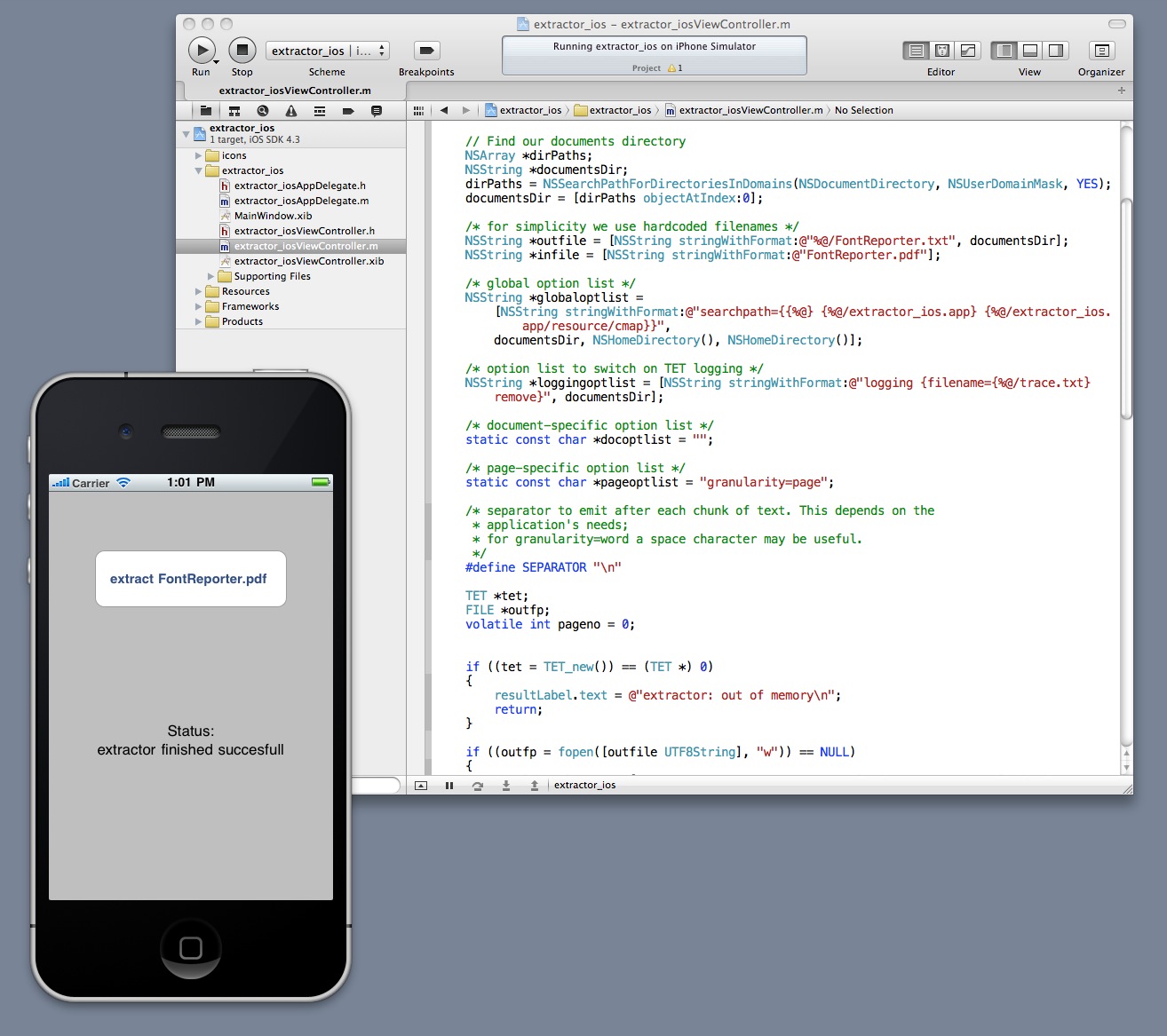
TET for Mobile and Embedded Platforms
PDFlib TET (Text and Image Extraction Toolkit) reliably extracts text, images and metadata from PDF documents. TET makes available the text contents of a PDF as Unicode strings, plus detailed color, glyph and font information as well as the position on the page. Raster images are extracted in common image formats. TET optionally converts PDF documents to an XML-based format called TETML which contains text and metadata as well as resource information.
TET contains advanced content analysis algorithms for determining word boundaries, grouping text into columns and removing redundant text. Using the integrated pCOS interface you can retrieve arbitrary objects from the PDF, such as metadata, interactive elements, etc.
Evaluation & Pricing
Evaluation packages for all supported mobile and embedded systems are available here. For TET prices for mobile and embedded systems please contact sales@pdflib.com.
Examples for using TET on Mobile and Embedded Systems
As PDF files also become widely used on mobile devices there are different scenarios how TET can be used on mobile and embedded systems.
TET: Extract Text from PDF Documents as XML
PDFlib TET can be used to extract text and images from any PDF document and make them available for re-purposing.
PDF Attachments in an e-Mail
The content of PDF attachments can be made available for repurposing by PDFlib TET.
TET in Combination with PDFlib+PDI: Find Text and change PDF Documents
As TET extracts the text from a PDF document, it can also be used to make changes based on specific keywords. For this a combination of TET and PDFlib+PDI is used. Once a keyword is located in a given PDF, PDFlib+PDI can import that PDF and make some changes in this specific location reported by TET, for example add bookmarks. Then a new changed PDF can be generated. For examples how to do this please see our TET cookbook.